If you can forgive the overly-pretentious title, I’d like to tell you about the things I find beautiful.
Why? Well, it turned out that pretty recently I discovered that for the past few years I’ve been growing fascinated by an alarming number of topics across diverse areas. As I’ve become more and more self-aware, I wanted to locate the thing inside each of them which attracted me to them. Also, for the purpose of better self-discovery, I wanted to make a list of these things so that I could look back and revisit them again in the future.
As is common for almost every seemingly-novel intellectual pursuit, it turns out that there has already been someone in the past who has already thought of the same thing and written about it. (As a young boy when I noticed how often this was happening, I used to get sad that there was always someone else who beat me to everything I thought I had discovered for myself.)
Immanuel Kant says that things we find beautiful (aesthetic judgements) must have four distinguishing features. First, they are disinterested, meaning that we take pleasure in something because we judge it beautiful, rather than judging it beautiful because we find it pleasurable. Second and third, such judgments are both universal and necessary. This means roughly that it is an intrinsic part of the activity of such a judgment to expect others to agree with us. Fourth, through aesthetic judgments, beautiful objects appear to be ‘purposive without purpose’ (sometimes translated as ‘final without end’).
The fourth and final feature is common to the aesthetics of Schopenhauer too. (Although there are major matters on how Schopenhauer differs from Kant.) In a nutshell, Schopenhauer says that the conscious manifestation of the Will is evil, and that art offers a way for people to temporarily escape the suffering that results from willing. So there is sense in pursuing “art for art’s sake”.
This is something which I strongly and unconsciously believed in ever since I was introduced to Pure Mathematics. While I initially held the view that nothing could compare to the aesthetic experience (or “Joy”) which Mathematics could provide, in due course I realized that there were many many other things which could provide an equal, if not greater, amount of this “Joy”. The following is a list of the things I’ve come across so far in life which I find beautiful, in the sense described above: I believe that each of the items in the following list have an inherent value enough to warrant a study of each one for it’s own sake. Here they are in no particular order.
- The prose of Jorge Luis Borges: In particular, the structure and execution of his stories and poems. Each story of his has a a nugget of an idea which is breathtakingly creative, around which the story is weaved, with that mellifluous writing which is Borges’ own. It has been a long standing goal of mine to weave a story as intricate as his, although I’m sure it would only come across as a cheap replica of the original.
- The Fundamental Theorems of Asset Pricing: Two theorems which lie at the heart of Quantitative Finance and which specify conditions for the fair pricing of a contingent claim(i.e., without the possibility of arbitrage). More precisely, the theorems state that if a market model of a market has a risk-neutral martingale measure, then that market does not admit arbitrage in it’s pricing. Also, markets with a unique risk-neutral measure are precisely those in which every derivative instrument can be hedged.
- Grothendieck dessins d’enfant: Graph embeddings in Riemann surfaces which provide combinatorial invariants for the action of the mysterious absolute Galois group over the rationals,
! Unexpected and beautiful.
- Conlangs/Lojban/Sapir-Whorf Hypothesis: Conlangs are human constructed languages. One of the crowning achievements of human thought is the construction of Lojban, a language based on first-order logic in which it is impossible to be ambiguous. (For example, the grammar prohibits you saying things like “I got a license to practice in New York.” because there are two ways in which that sentence can be interpreted!) The Sapir-Whorf hypothesis is a rather controversial statement on the possibility of language influencing our thoughts. If this was true, would Lojban be able to influence its speaker’s thoughts and make them think critically and correctly by default?
- Homotopy Type Theory and Univalent Foundations: Around 2005, it was discovered that traditional Martin-Löf Type Theory has a natural interpretation ( a “model”) in the abstract homotopy theory of Simplicial sets. Via this model, it was discovered that Martin-Löf Type Theory could be extended by an axiom called the “Univalence Axiom”, which provides the correction notion of equality in the universe of types. This new and extremely exciting area of mathematics which brings together abstract Homotopy Theory (an offspring of algebraic topology) and Type Theory (from Theoretical Computer Science) is called Homotopy Type Theory. Closely related to HoTT is the Univalent Foundations project which is an attempt to systematically provide a new constructive foundations of mathematics using, as a key way, the notions of h-level and Univalence. In particular, it provides a possibility of computer verification of mathematical proofs. The long term goal of this project is to make formal verification of mathematical proofs ubiquitous.
- Haskell and Functional Programming: Why functional programming? Tail recursion is it’s own reward.
- Horology and George Daniels: Kicked off after I saw Daniels talk about the story behind the Space Traveller’s Watch. Daniels was one of the few people in the world who could make a complete watch by hand during his time.
- Astronomy/Eclipse Prediction/Star Trails:
- When I bought a DSLR, I experimented with long exposure photography and photographed my first star trails in the Rann of Kutch, in Gujarat. It’s so beautiful watching the stars rotate about the pole star.
- On a whim, I decided to understand how eclipses were predicted. Which led me to borrowing a textbook on Spherical Astronomy. I discovered in that book the Saros cycle and the Besselian elements
- The Philosophy of Philip Mainlander: Philip Mainlander propounded “Perhaps the most radical system of pessimism known to philosophical literature…” Mainländer proclaims that life is absolutely worthless, and that “the will, ignited by the knowledge that non-being is better than being, is the supreme principle of morality”. In particular he states that God Himself finds existence unbearable and as a result He created the universe. So we are God’s way of killing Himself.
- Software-Defined Radio: SDRs are awesome! They allow fully software implmentations of what previously required specialized and expensive hardware. I bought my HackRF last September and have been in love ever since.
I guess I’ll update the list as and when I discover more about myself.
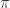 exists because we have
exists because we have 
 , because it can never be completed. Here is an example of a conversation (taken from Harvey M. Friedman “Philosophical Problems in Logic”) with a well known Ultrafinitist,
, because it can never be completed. Here is an example of a conversation (taken from Harvey M. Friedman “Philosophical Problems in Logic”) with a well known Ultrafinitist,  is said to follow a power law if it’s density looks like
is said to follow a power law if it’s density looks like  Where
Where  and
and  is a normalizing constant. We assume
is a normalizing constant. We assume  the density diverges and so that equation cannot hold for all
the density diverges and so that equation cannot hold for all 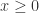 and hence, there must be a quantity
and hence, there must be a quantity  such that the above power law behaviour is followed.
such that the above power law behaviour is followed. where
where  is the generalized Hurwitz zeta function. So the parameters of a power law are
is the generalized Hurwitz zeta function. So the parameters of a power law are 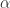 and
and  . If we suspect that our data comes from a power law, we first need to estimate the quantities
. If we suspect that our data comes from a power law, we first need to estimate the quantities 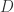 between the data and the fit.
between the data and the fit.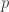 -value. Check if this
-value. Check if this  and
and 
 and the
and the  . So we reject stretched exponential.
. So we reject stretched exponential. and the
and the  . So we reject exponential.
. So we reject exponential. and the
and the  . So we reject lognormal positive.
. So we reject lognormal positive. and the
and the  .
. largest value of
largest value of  for the first few
for the first few  and parameters
and parameters  . Of course, this does not hold for any discrete random variable
. Of course, this does not hold for any discrete random variable 


 and
and 


{kind=link}